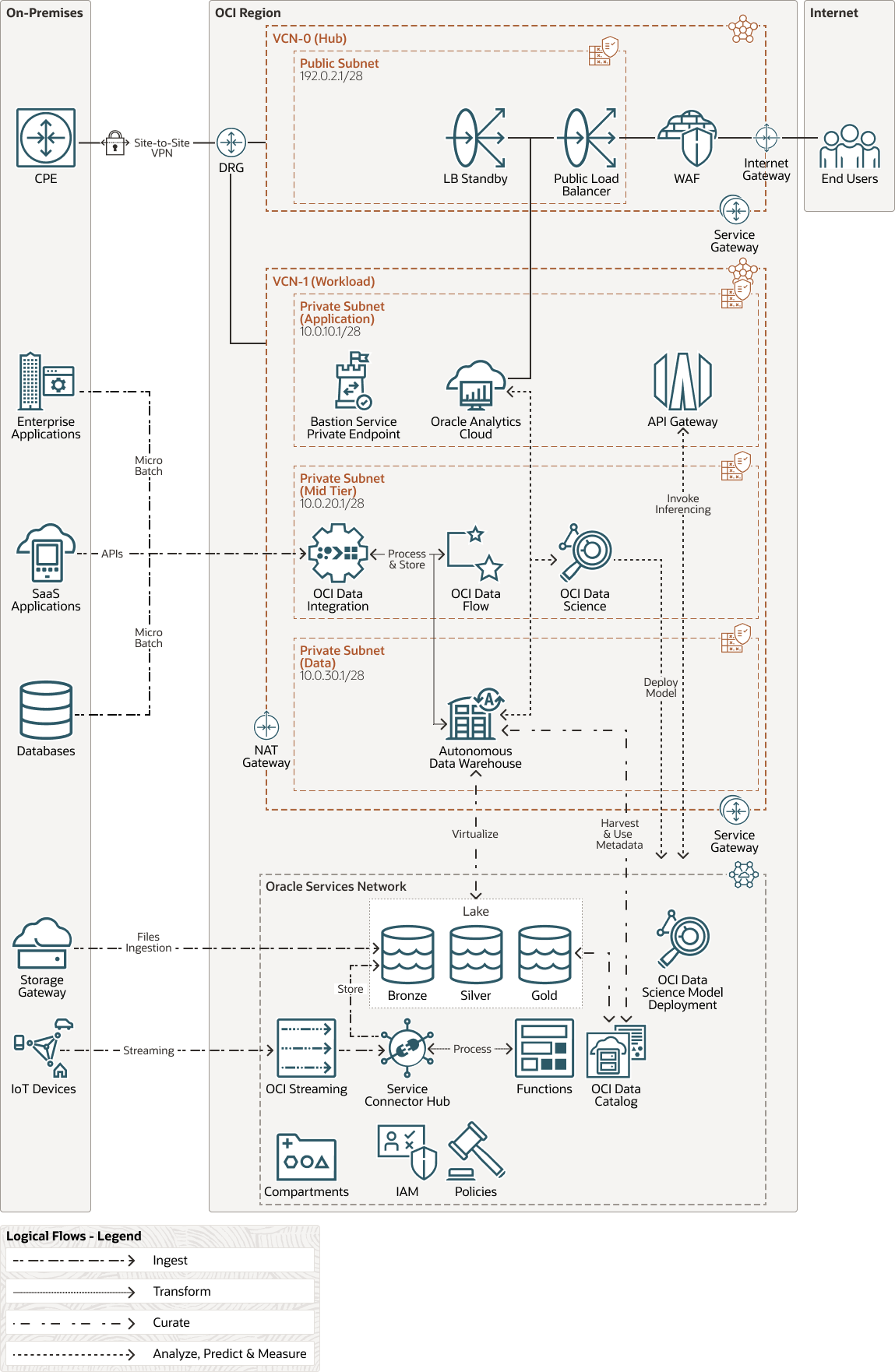
Oracle Autonomous Data Warehouse This architecture uses Oracle Autonomous Data Warehouse on shared infrastructure.
- Enable auto scaling to give the database workloads up to three times the processing power.
- Consider using Oracle Autonomous Data Warehouse on dedicated infrastructure if you want the self-service database capability within a private database cloud environment running on the public cloud.
- Consider using the hybrid partitioned tables feature of Autonomous Data Warehouse to move partitions of data to Oracle Cloud Infrastructure Object Storage and serve them to users and applications transparently. We recommend that you use this feature for data that is not often consumed and for which you don't need the same performance as for data stored within Autonomous Data Warehouse .
- Consider using the external tables feature to consume data stored in Oracle Cloud Infrastructure Object Storage in real time without the need to replicate it to Autonomous Data Warehouse . This feature transparently and seamlessly joins data sets curated outside of Autonomous Data Warehouse , regardless of the format (parquet, avro, orc, json, csv, and so on), with data residing Autonomous Data Warehouse .
- Consider using Autonomous Data Lake Accelerator when consuming object storage data to deliver an improved and faster experience to users consuming and joining data between the data warehouse and the data lake.
- Consider using Analytic Views to model semantically the DW star or snowflake underlying schema directly in ADW so that granular data is automatically aggregated without the need to preaggregate it, the semantic model is consumed by using SQL consistently with any SQL compliant client, including Oracle Analytics Cloud, ensuring facts and KPIs are served consistently regardless of the client, and all data can be used on the semantic model regardless if it is stored in ADW or in Object Storage making this feature a perfect semantic modeling layer for a lakehouse architecture where facts and dimensions can traverse both the DW and the Lake.
- Consider using Customer Managed Keys leveraging the Vault service if a full control of ADW encryption keys is needed due to company or regulation policies.
- Consider using Database Vault in ADW to prevent unauthorized privileged users from accessing sensitive data and thus prevent data exfiltration and data breaches.
- Consider using Autonomous Data Guard to support a business continuity plan via setting up and keeping data replicated on a standby instance either on the same region or on another region.
- Consider using dynamic data masking with Data Redaction to serve masked data to users depending on their role and hence guaranteeing appropriate data access without the need for data duplication and static masking.
- Consider organizing your lake across different sets of buckets leveraging a medallion architecture (bronze, silver, gold) or other partitioning logic to segregate data based on its quality and enrichment, enforce fine-grained security for consumers reading the data, and apply different lifecycle management policies to the different tiers.
- Consider using different object storage tiers and lifecycle policies to optimize costs of storing lake data at scale.
- Consider using Customer Managed Keys leveraging the Vault service if a full control of Object Storage encryption keys is needed due to company or regulation policies.
- Consider using Object Storage replication to support a business continuity plan via setting up bucket replication to another region. Since Object Storage is highly durable and maintains several copies of the same object in a single region for recovery on the same region bucket replication is not needed.
- Consider using AutoML in OCI Data Science or Oracle Machine Learning to speed up ML model development.
- Consider using Open Neural Networks Exchange (ONNX) for interoperability. ONNX 3rd party models can be deployed either into OML and exposed as a REST endpoint or into OCI Data Science and exposed as an HTTP endpoint.
- Consider saving the model in OCI Data Science as ONNX and import it into OCI GoldenGate Stream Analytics if there is a need to run scoring and prediction in a real time data pipeline to have more timely predictions that can drive real time business outcomes.
- Consider using OCI Data Science Conda environments for better management and packaging of Python dependencies inside Jupyter notebook sessions. Leverage the Anaconda curated repository of packages within OCI Data Science to use your favorite open-source tools to build, train, and deploy models.
- Consider using OCI Data Flow within the Data Science Jupyter environment to perform Exploratory Data Analysis, data profiling and data preparation at scale leveraging Spark scale out processing.
- Consider using Data Labeling to label data such as images, text or documents and use it to train ML models built on OCI Data Science or OCI AI Services and thus improving the accuracy of predictions.
- Consider deploying an API Gateway to secure and govern the consumption of the deployed model if real-time predictions are being consumed by partners and external entities.
- Leverage the Oracle Cloud Infrastructure Data Integration to coordinate and schedule Oracle Cloud Infrastructure Data Flow application runs and be able to mix and match declarative ETL with custom Spark code logic. Use functions from within Oracle Cloud Infrastructure Data Integration to further extend the capabilities of data pipelines.
- Consider using SQL pushdown for transformations that have ADW as target to use an ELT approach that is more efficient, performant and secure compared with ETL.
- Consider allowing OCI Data Integration to handle data sources schema drift in order to have more resilient and future proof data pipelines that will sustain data sources schema changes.
- Consider using Oracle Cloud Infrastructure Data Catalog as a Hive metastore for Oracle Cloud Infrastructure Data Flow in order to securely store and retrieve schema definitions for objects in unstructured and semi-structured data assets such as Oracle Cloud Infrastructure Object Storage .
- Consider using Delta Lake on OCI Data Flow if ACID transactions and unification of streaming and batch processing is needed for lake data.
- Consider using autoscaling to automatically scale horizontally or vertically the worker nodes based on metrics or schedule to continuously optimize costs based on resources demand.
- Consider using the OCI HDFS connector for Object Storage to read and write data to and from Object Storage an thus providing a mechanism to produce/consume data shared with other OCI services without the need to replicate and duplicate it.
- Consider using Delta Lake on OCI BDS if ACID transactions and unification of streaming and batch processing is needed for lake data.
- For predictive maintenance and anomaly detection use cases, consider using the Oracle Cloud Infrastructure Anomaly Detection service that helps identifying anomalies in a multivariate data set by taking advantage of the interrelationship among signals.
- Consider using Data Labeling to label train data that will be used to tune and get more accurate predictions for AI Services such as Vision, Document Understanding and Language.
- Consider using Oracle Cloud Infrastructure Functions to add run-time logic eventually needed to support specific API processing that is out of scope of the data processing and access and interpretation layers.
- Consider using Usage Plans to manage subscriber access to APIs, to monitor and manage API consumption, set up different access tiers for different consumers and support data monetization by tracking usage metrics that can be provided to an external billing system.
Considerations
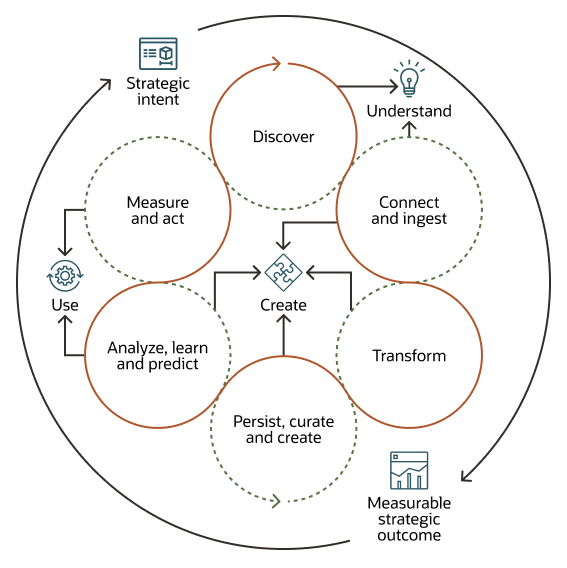
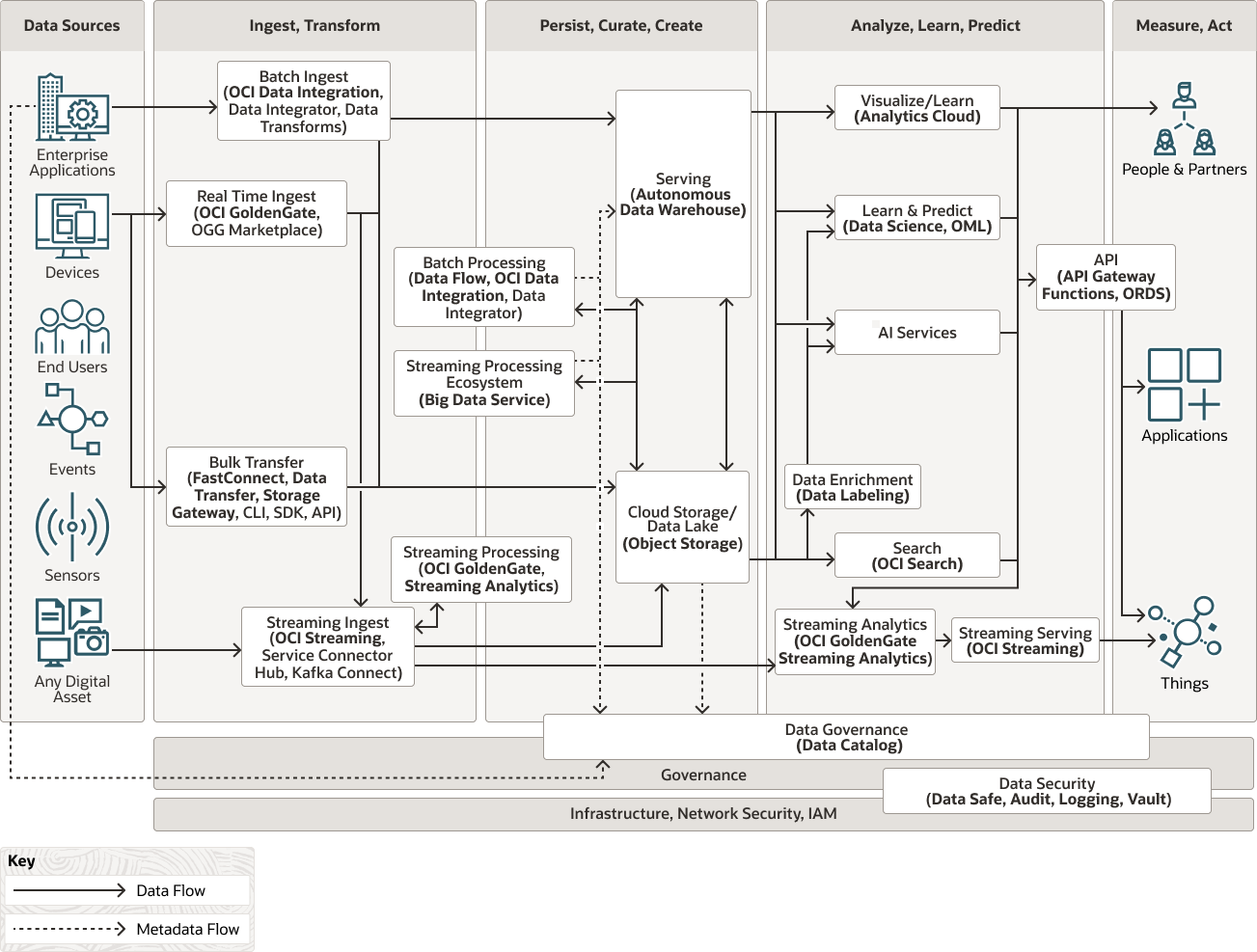
When collecting, processing, and curating application data for analysis and machine learning, consider the following implementation options.
Oracle Cloud Infrastructure Data Integration provides a cloud native, serverless, fully-managed ETL platform that is scalable and cost efficient.
Oracle Cloud Infrastructure GoldenGate provides a cloud native, serverless, fully-managed, non-intrusive data replication platform that is scalable, cost efficient and can be deployed in hybrid environments.
Oracle Autonomous Data Warehouse is an easy-to-use, fully autonomous database that scales elastically, delivers fast query performance, and requires no database administration. It also offers direct access to the data from object storage external or hybrid partitioned tables.
Oracle Cloud Infrastructure Object Storage stores unlimited data in raw format.
Oracle Cloud Infrastructure Data Integration provides a cloud native, serverless, fully-managed ETL platform that is scalable and cost effective.
Oracle Cloud Infrastructure Data Flow provides a serverless Spark environment to process data at scale with a pay-per-use, extremely elastic model.
Oracle Cloud Infrastructure Big Data Service provides enterprise-grade Hadoop-as-a-service with end-to-end security, high performance, and ease of management and upgradeability.
Oracle Analytics Cloud is fully managed and tightly integrated with the curated data in Oracle Autonomous Data Warehouse .
Data Science is a fully-managed, self-service platform for data science teams to build, train, and manage machine learning (ML) models in Oracle Cloud Infrastructure . The Data Science service provides infrastructure and data science tools such as AutoML and model deployment capabilities.
Oracle Machine Learning is a fully-managed, self service platform for data science available with Oracle Autonomous Data Warehouse that leverages the processing power of the warehouse to build, train, test, and deploy ML models at scale without the need to move the data outside of the warehouse.
Oracle Cloud Infrastructure AI services are a set of services that provide pre-built models specifically built and trained to perform tasks such as inferencing potential anomalies or detecting sentiment.
Deploy
The Terraform code for this reference architecture is available in GitHub. You can pull the code into Oracle Cloud Infrastructure Resource Manager with a single click, create the stack, and deploy it. Alternatively, you can download the code from GitHub to your computer, customize the code, and deploy the architecture by using the Terraform CLI.

- Deploy by using Oracle Cloud Infrastructure Resource Manager :
- Click If you aren't already signed in, enter the tenancy and user credentials.
- Review and accept the terms and conditions.
- Select the region where you want to deploy the stack.
- Follow the on-screen prompts and instructions to create the stack.
- After creating the stack, click Terraform Actions , and select Plan .
- Wait for the job to be completed, and review the plan. To make any changes, return to the Stack Details page, click Edit Stack , and make the required changes. Then, run the Plan action again.
- If no further changes are necessary, return to the Stack Details page, click Terraform Actions , and select Apply .
- Deploy by using the Terraform CLI:
- Go to GitHub.
- Clone or download the repository to your local computer.
- Follow the instructions in the README document.
Explore More
Learn more about the features of this architecture and about related architectures.
- Oracle Data Platform
- Learn about designing data lakes in Oracle Cloud
- Secure your workloads using Oracle Cloud Infrastructure Network Firewall Service
- Deploy a secure landing zone that meets the CIS Foundations Benchmark for Oracle Cloud
- Best practices framework for Oracle Cloud Infrastructure
- Oracle Cloud Infrastructure documentation
- Oracle Cloud Cost Estimator